Unmatched implementation speed
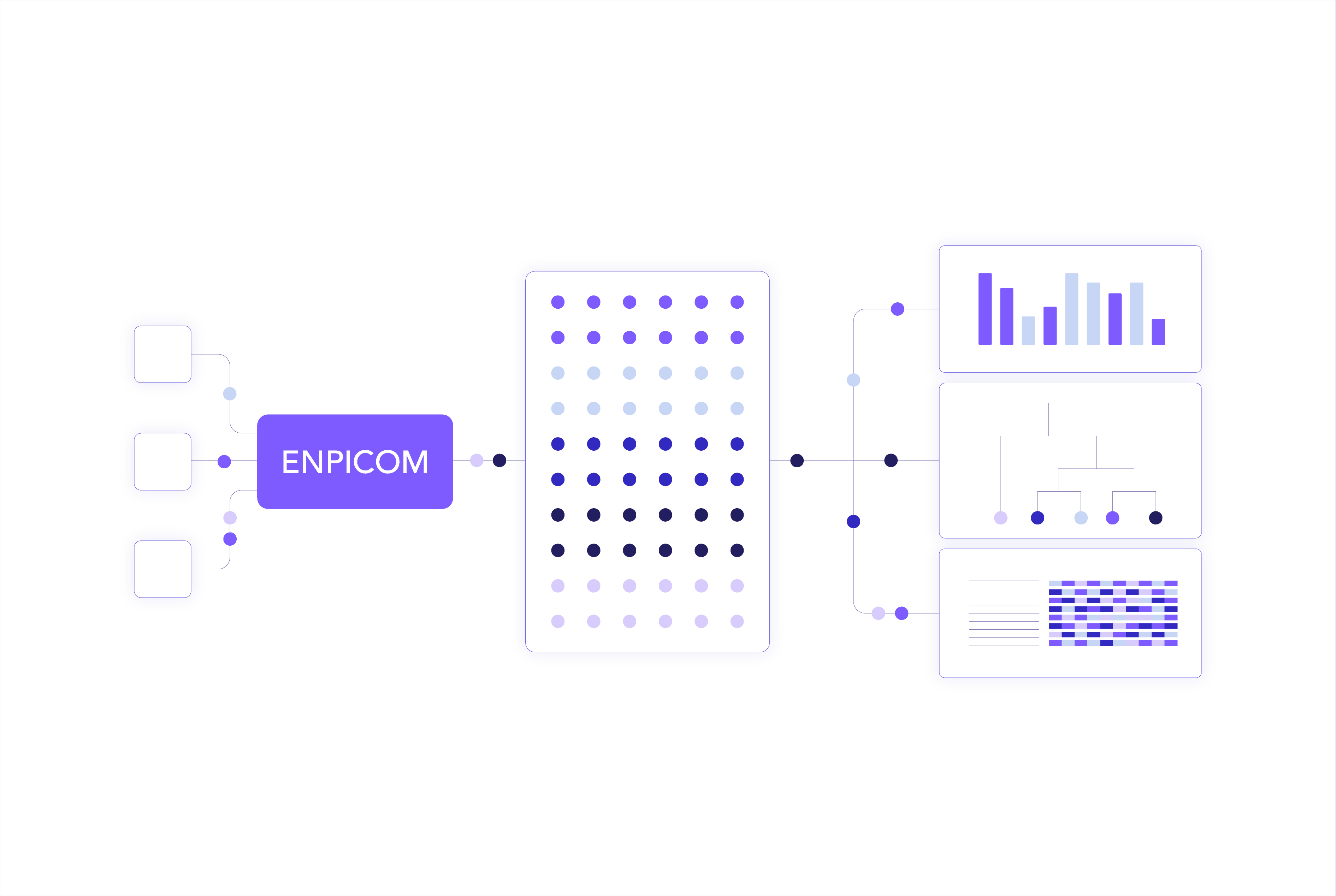
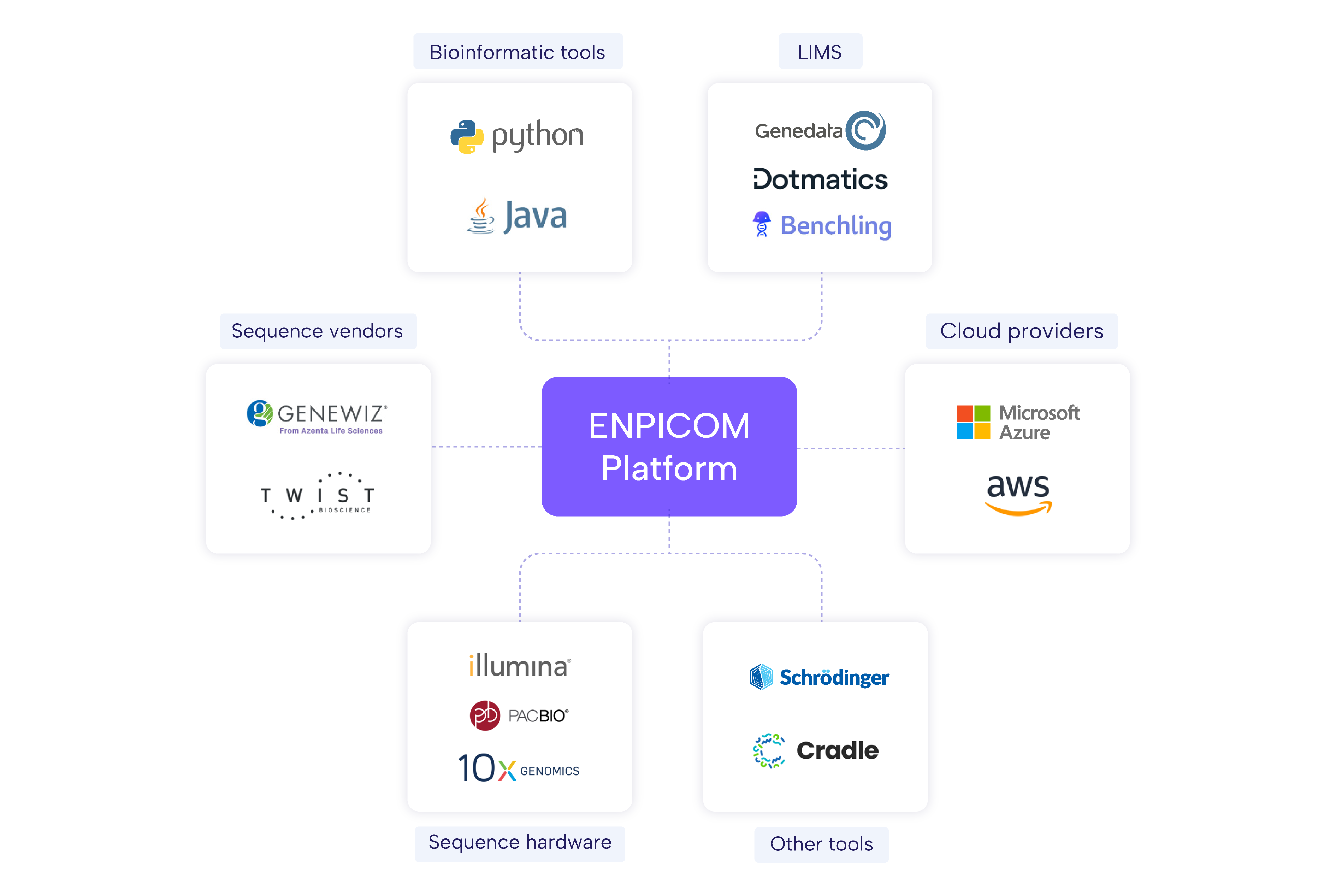
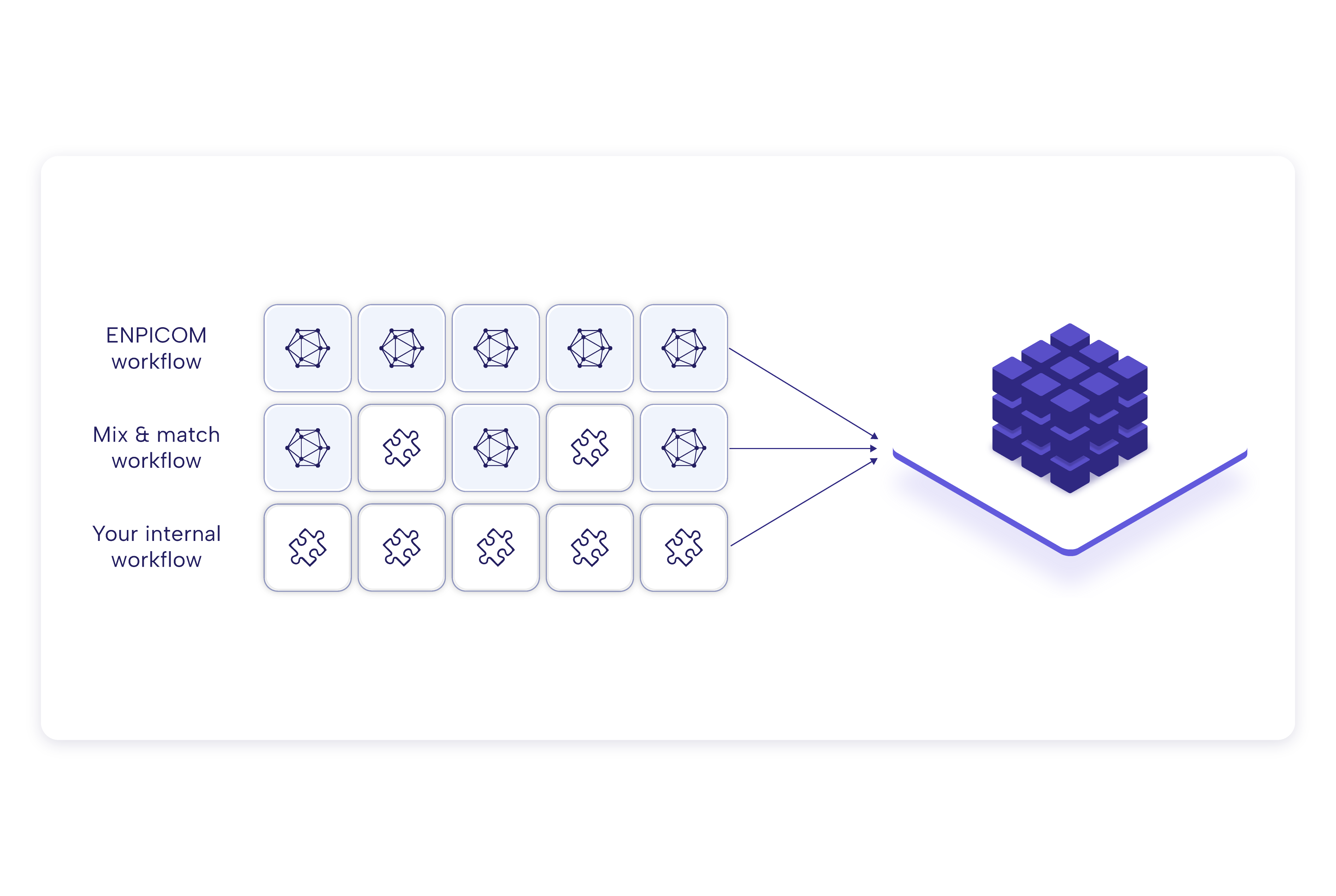
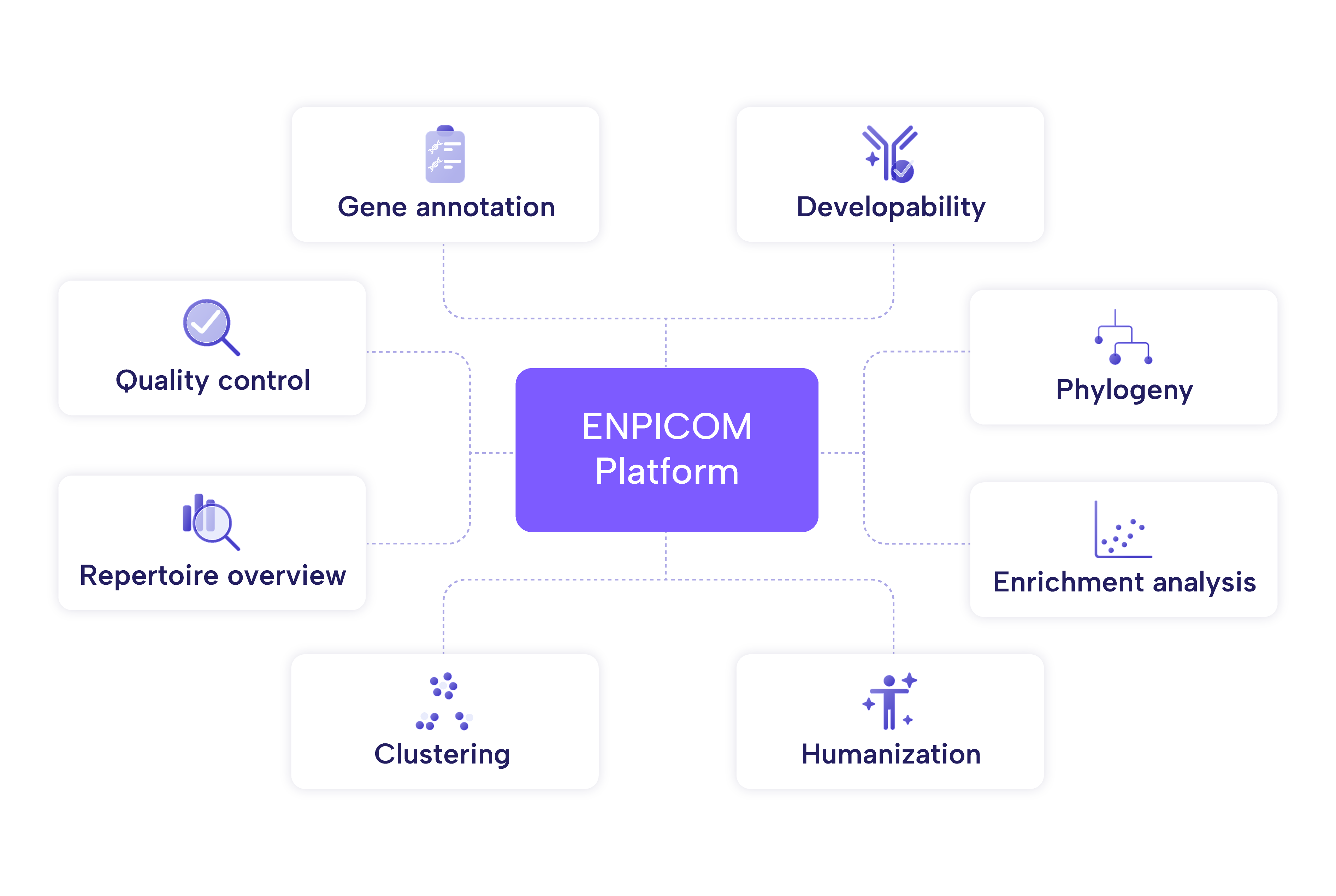
Historical software solutions are often developed at a static, slow-evolving pace. Traditional workflow rollouts and customizations can take years, delaying discovery and progress. Our team has the expertise to continuously advance our solutions, cut through complexity to deliver fully operational workflows in just a few months, without compromising flexibility or performance.