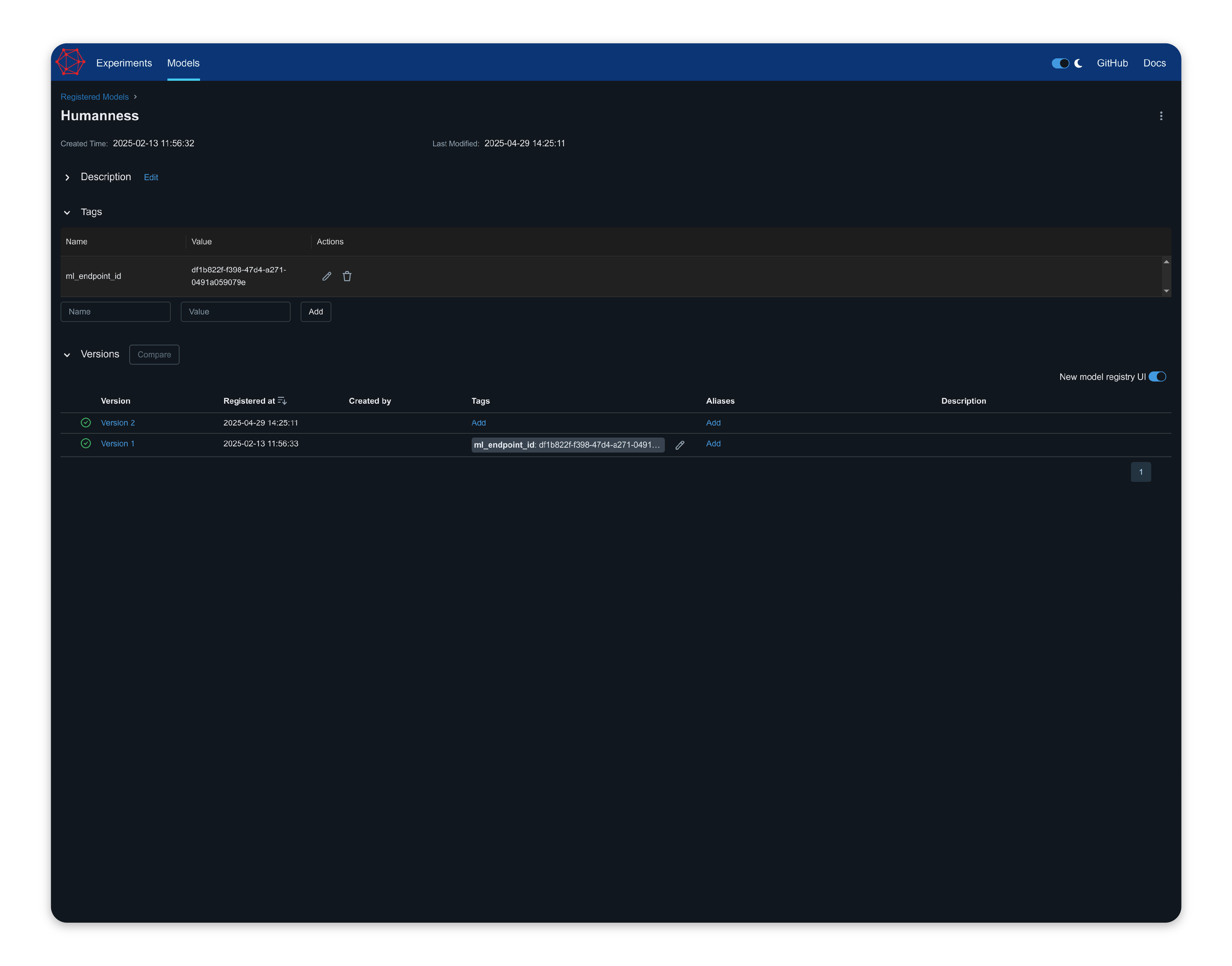
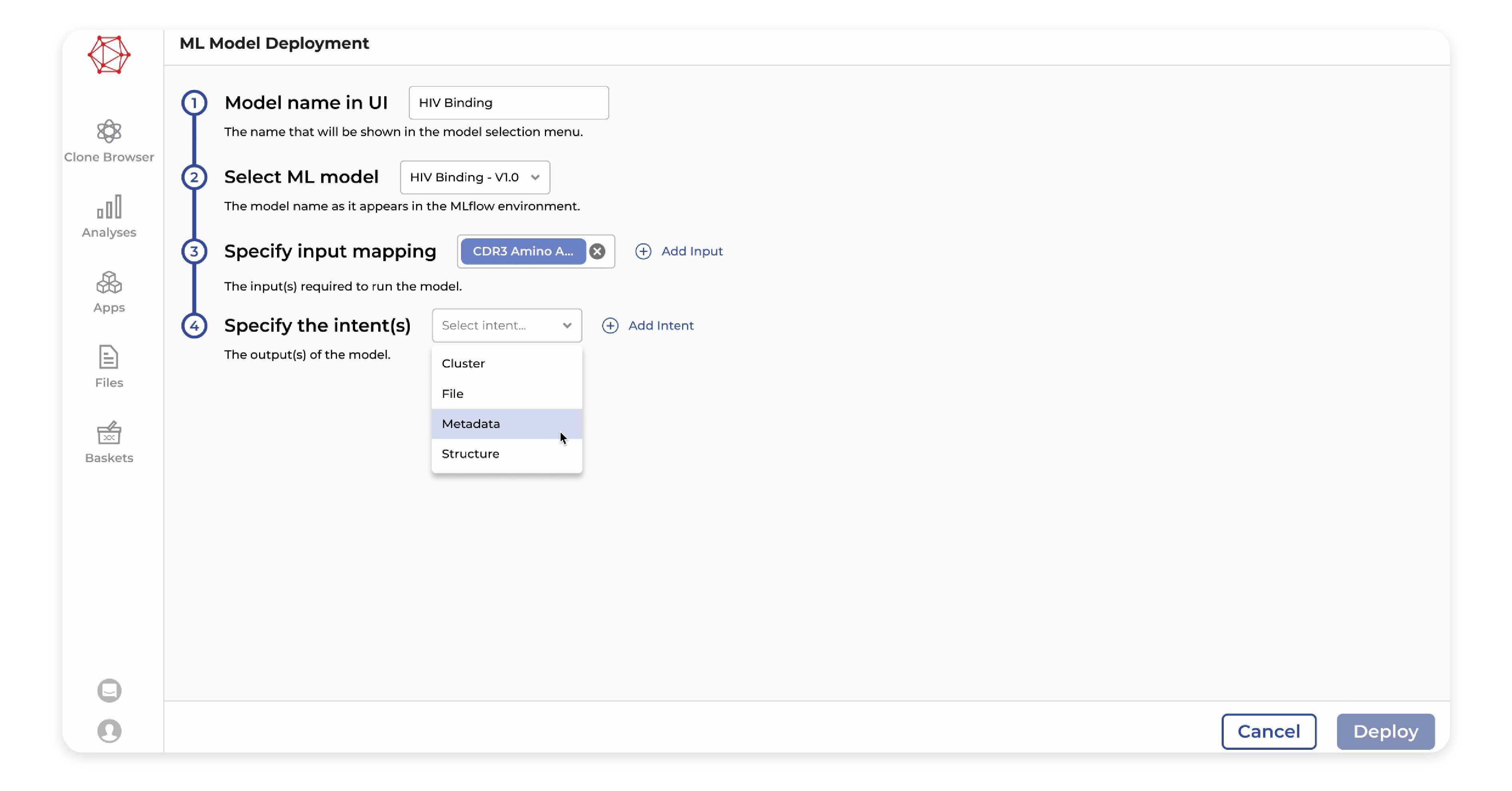
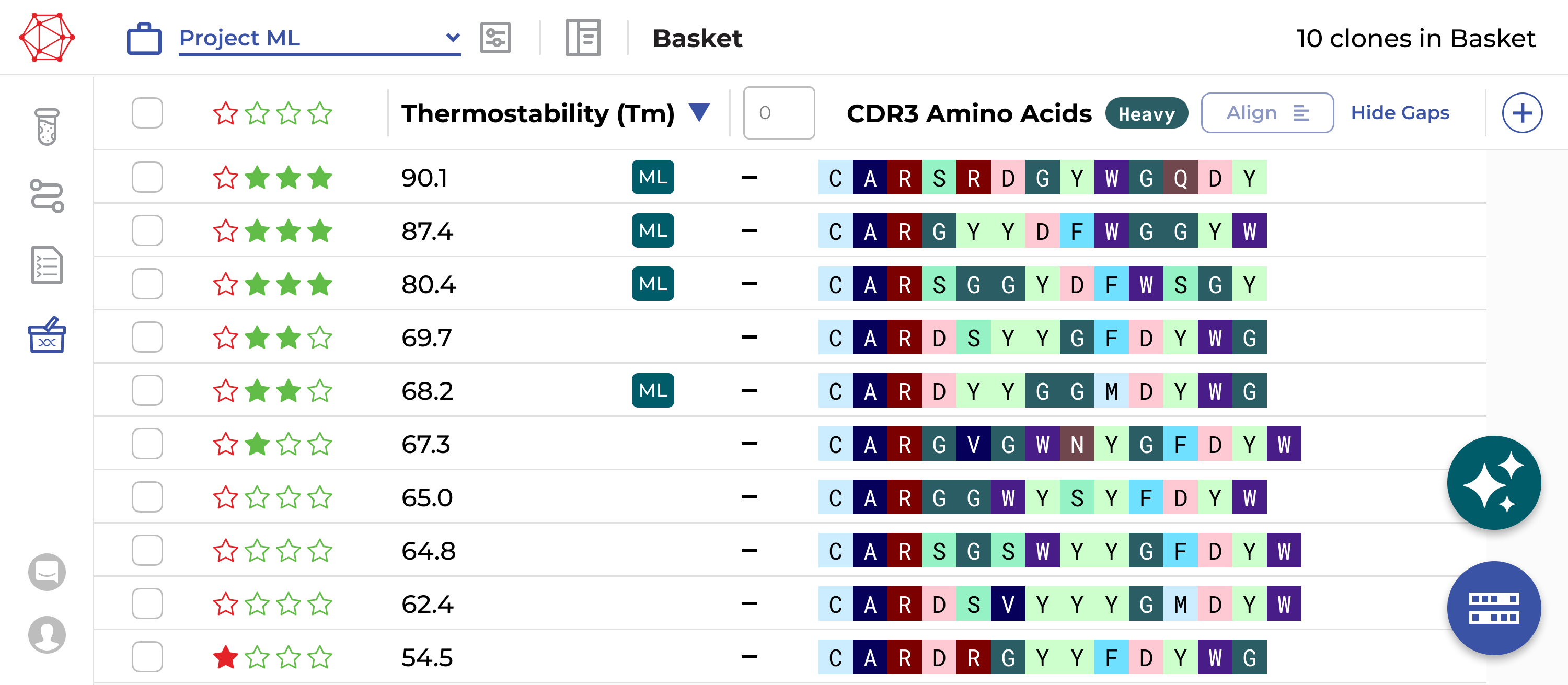
Skip to navigation
Skip to content
ENPICOM ENPICOM
Schedule a demo
ENPICOM
Schedule a demo
Menu
- Why ENPICOM
- Software & Services
- Use cases
-
AI integration
Biologics research
-
- Resources
- Company