Panning complexity outpaces the tools
Multi-round, multi-condition campaigns generate datasets that need flexible, user-defined comparisons. Static tools force you to flatten that complexity or work around it manually.
From in vitro display libraries to in vivo immune repertoires — process raw NGS into a ranked set of developable candidates, all in one platform.
In vitro antibody discovery
From raw NGS to ranked candidates. Find enriched clones without liabilities.

Multi-round, multi-condition campaigns generate datasets that need flexible, user-defined comparisons. Static tools force you to flatten that complexity or work around it manually.
High-frequency clones are fast growers, not necessarily strong binders. Without the right enrichment analysis, the best candidates stay buried in your data.
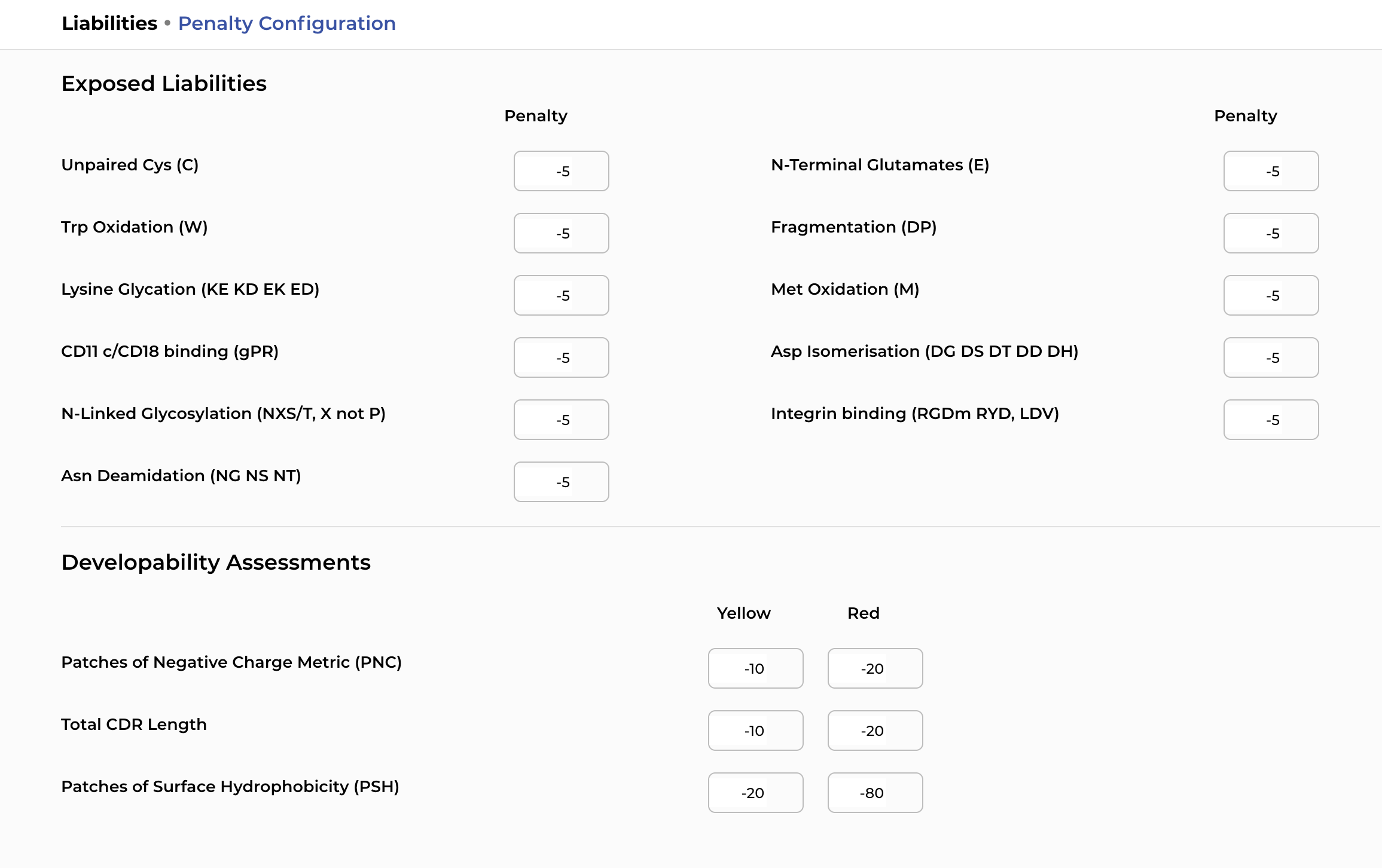
Sequence liabilities that slip through early selection cause failures deep in development. Catching them at the clone selection stage is where it matters.
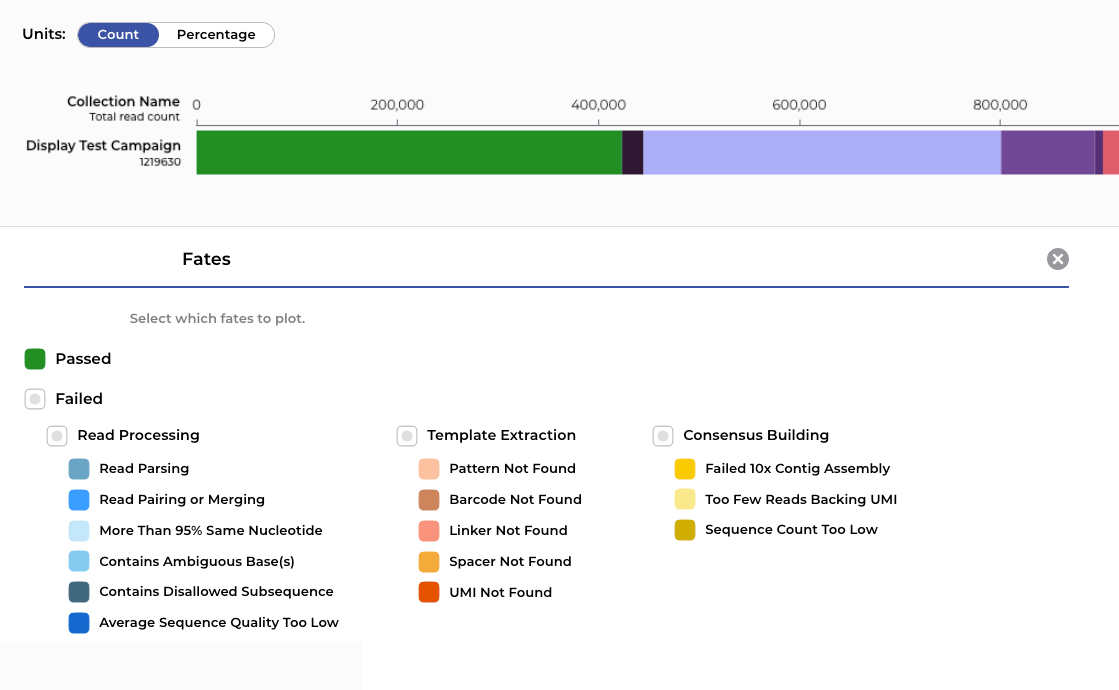
Antigen concentration, blocking conditions, round number, assay results — panning campaigns generate rich metadata. Cross-comparing all of it in a spreadsheet isn't just slow, it's practically impossible.
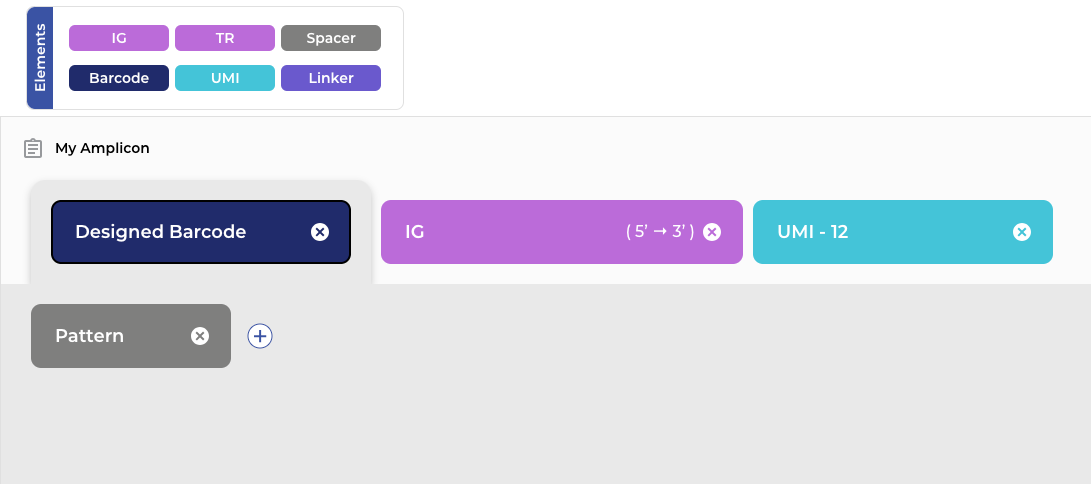
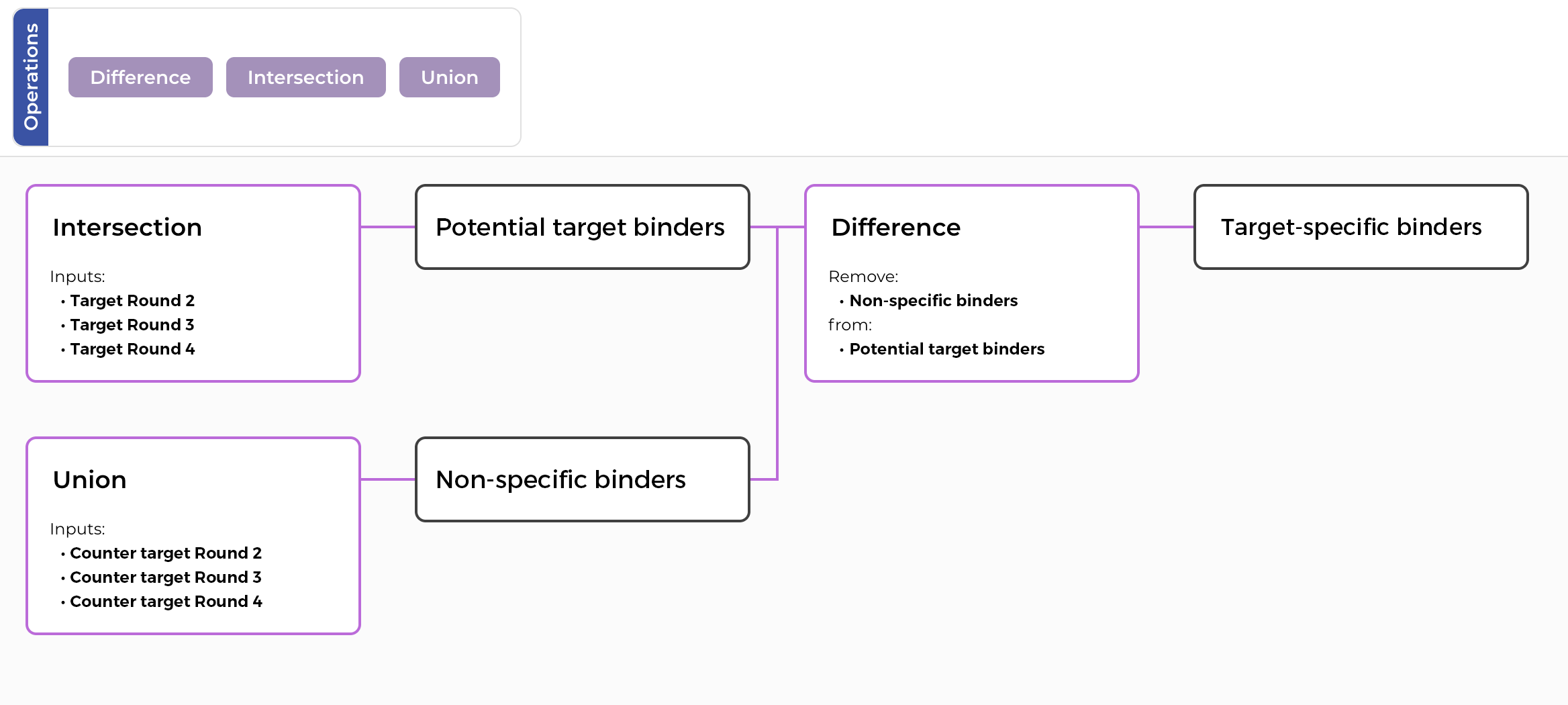
Build your panning campaign in a flexible analysis environment — multiple rounds, targets, and counter-selections, no matter how complex the design. Overlay enrichment scores, assay results, and liability predictions in interactive visualizations, and make decisions on promising candidates from a single screen.

In vivo antibody discovery
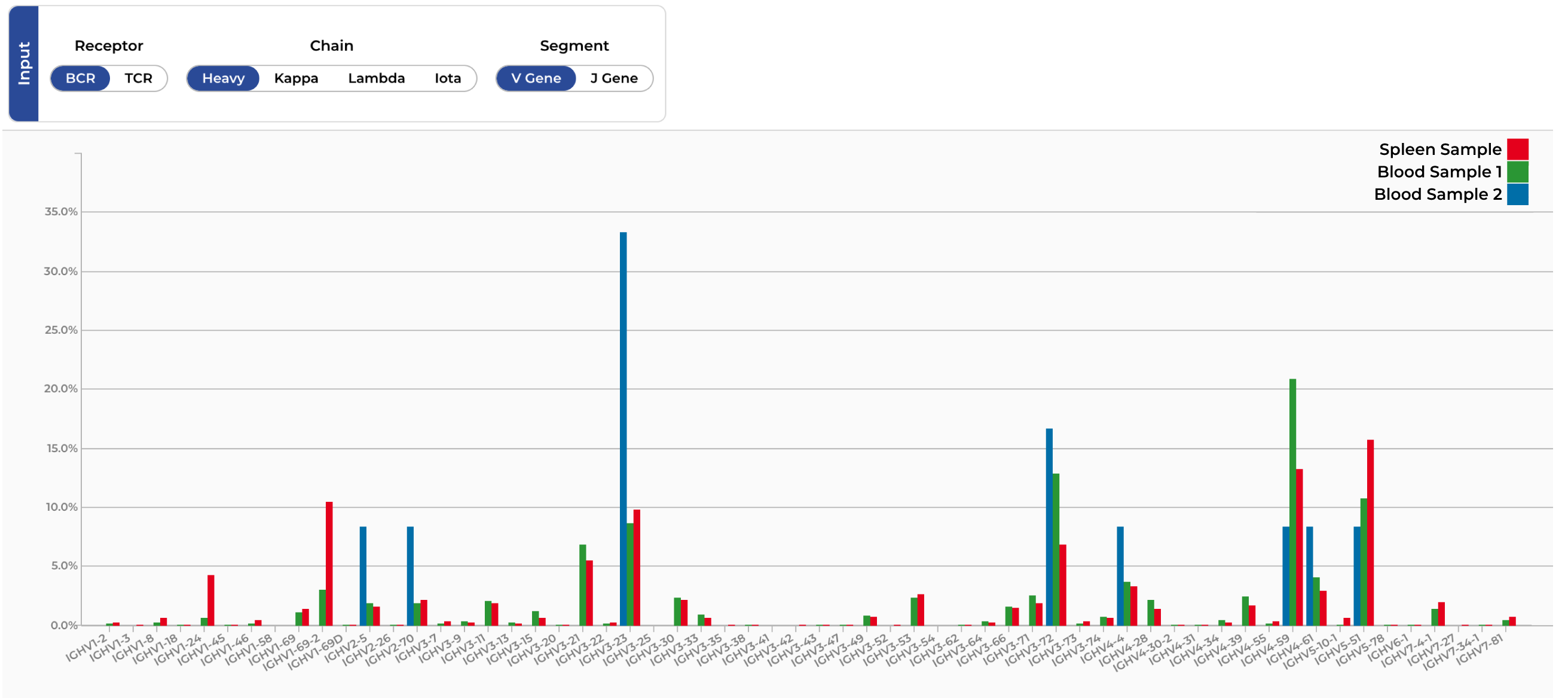
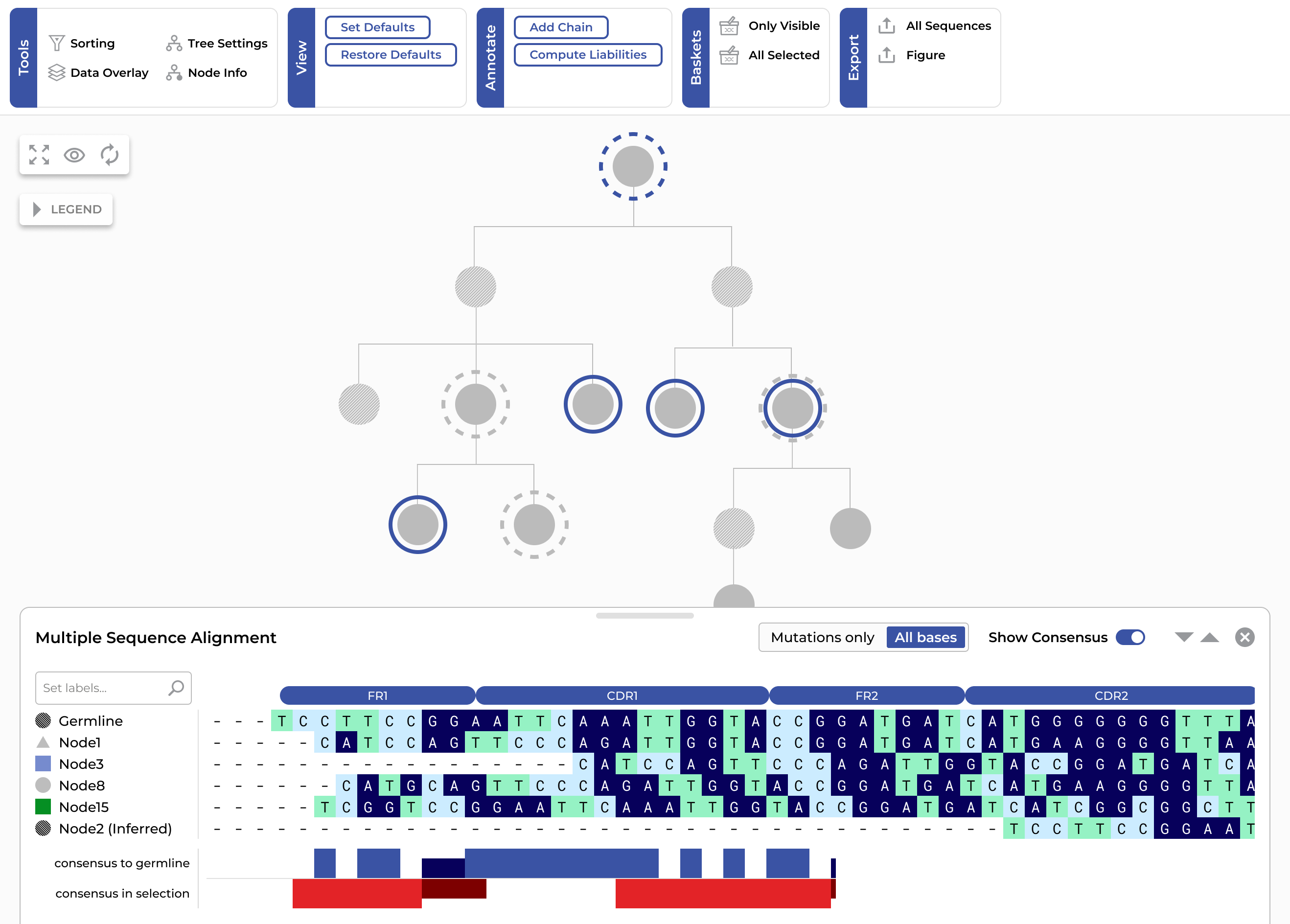
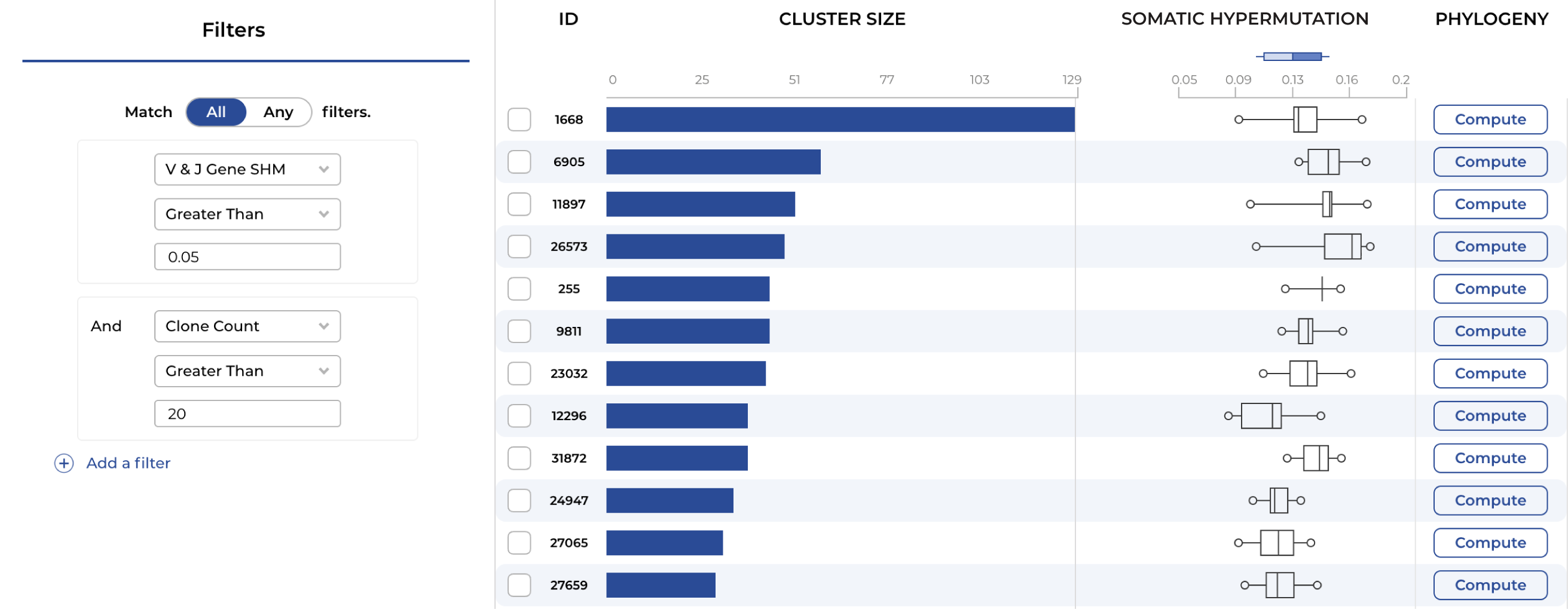
Explore lineages and track somatic hypermutation through interactive phylogenetic trees. Integrate bulk and single-cell data, overlay assay results, and select a diverse set of developable leads.

Tracing affinity maturation across animals and timepoints is hard. Without clear lineage tracking, picking the right branch is guesswork.
Thousands of clones across multiple animals, timepoints, and immunization conditions. Finding the signal in that noise is hard.
Sequence liabilities caught late are expensive. Overlay liability predictions during clone selection to cut that risk early.
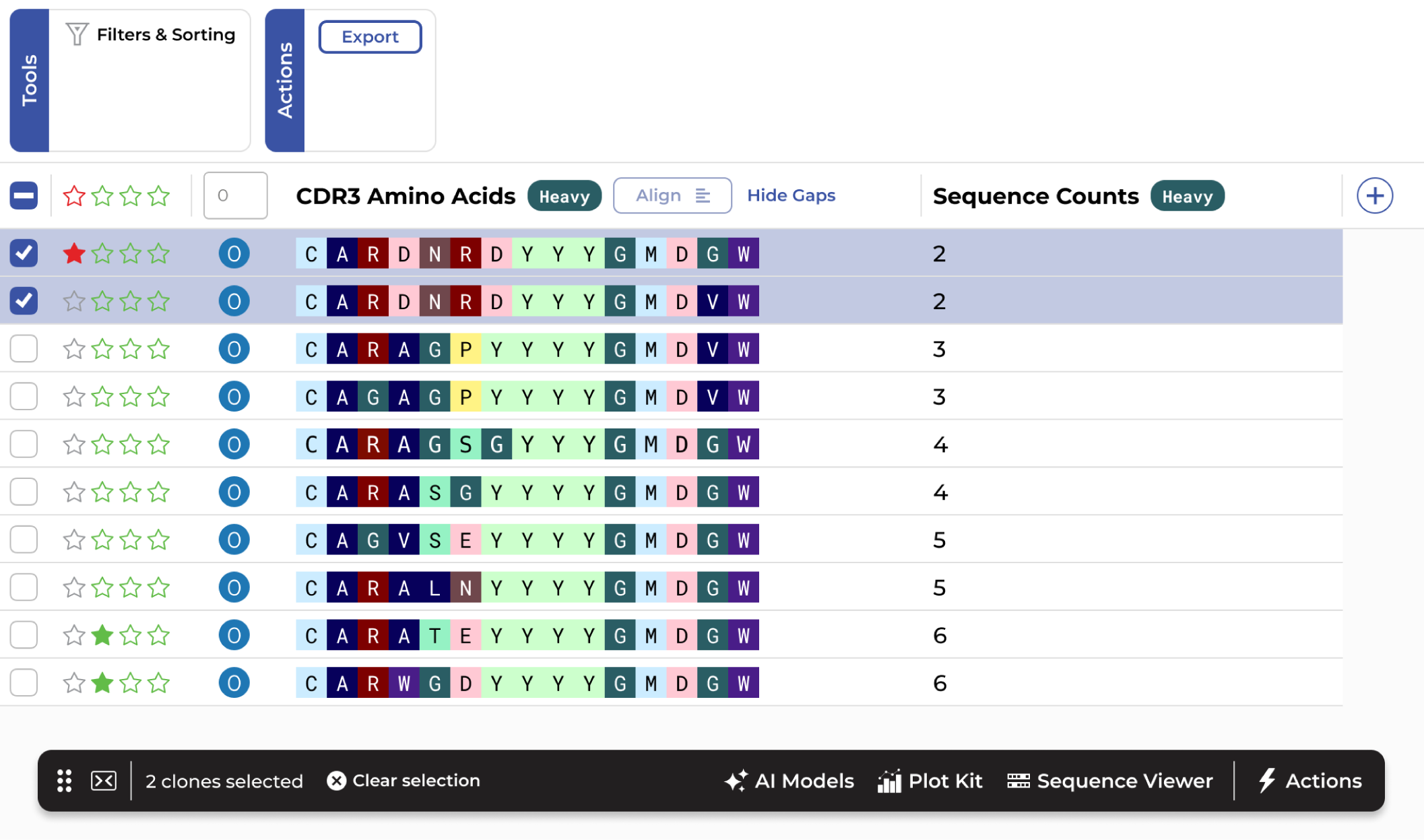
Dominant clones in a repertoire aren't necessarily the best binders or the most developable.
Selecting candidates that are truly structurally diverse requires more than just picking top clones by abundance or affinity.
Assay data, animal metadata, and immunization conditions all live separately from the sequence data, making informed decisions hard.
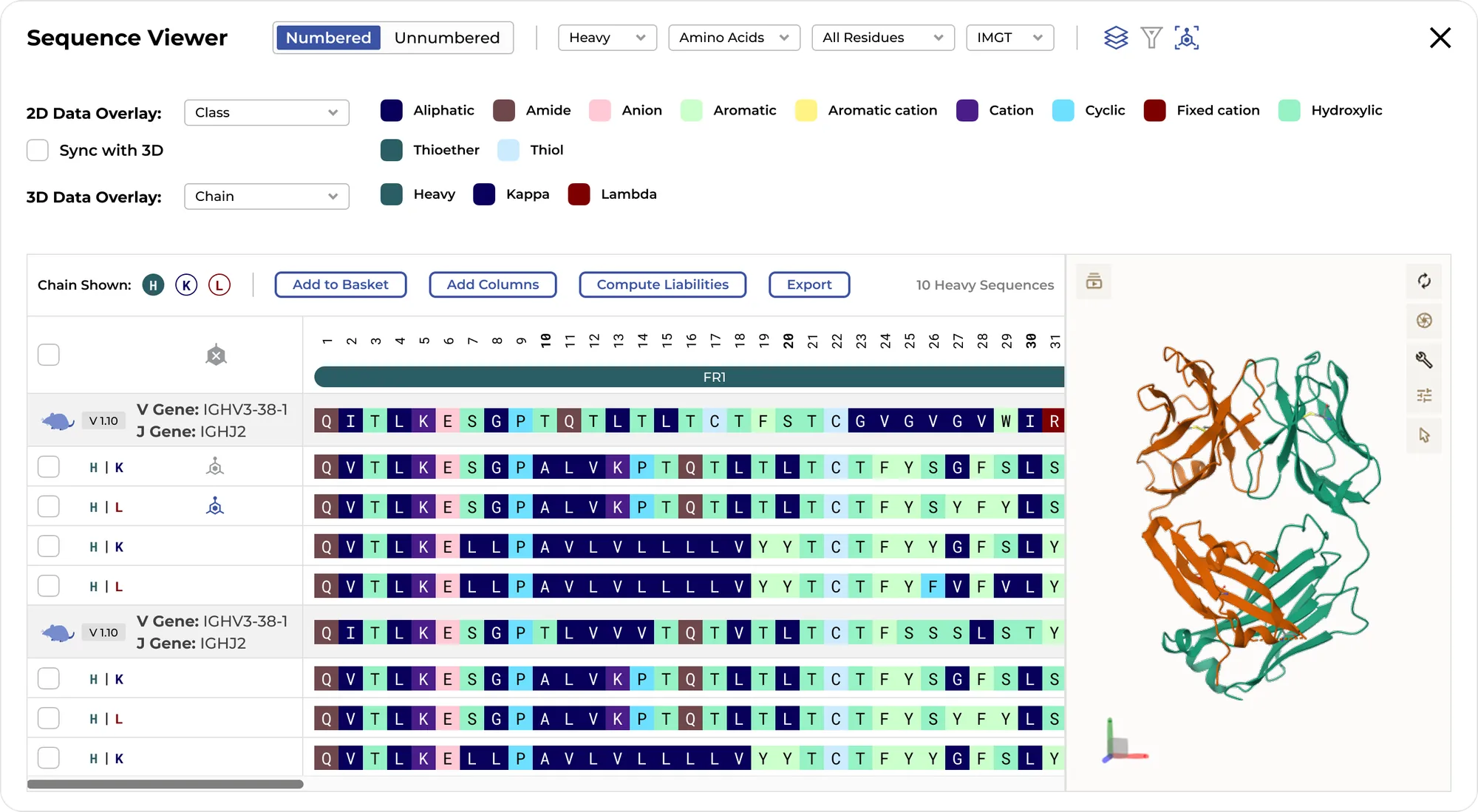
With the ENPICOM Platform, you can integrate any assay data from wet-lab experiments and compute structure-based developability profiles in silico. This information is seamlessly incorporated into your analysis workflow, creating information-rich visualizations in clustering, phylogeny, and the final selection of the optimal mix of diverse and developable hits.